
Page 334 - METODOLOGIA DE LA INVESTIGACION-Roberto Hernández Sampieri
P. 334
Paso 5: analizar mediante pruebas estadísticas las hipótesis planteadas (análisis estadístico inferencial) 303
¿Cómo se relacionan la distribución muestral
y el nivel de significancia?
El nivel de significancia o significación se expresa en términos de probabilidad (0.05 y 0.01) y la distri-
bución muestral también como probabilidad (el área total de ésta como 1.00). Pues bien, para ver si
existe o no confianza al generalizar acudimos a la distribución muestral, con una probabilidad ade-
cuada para la investigación. Dicho nivel lo tomamos como un área bajo la distribución muestral,
como se observa en la figura 10.16, y depende de si elegimos un nivel de 0.05 o de 0.01. Es decir, que
nuestro valor estimado en la muestra no se encuentre en el área de riesgo y estemos lejos del valor de
la distribución muestral, que insistimos es muy cercano al de la población.
Así, el nivel de significación representa áreas de riesgo o confianza en la distribución muestral.
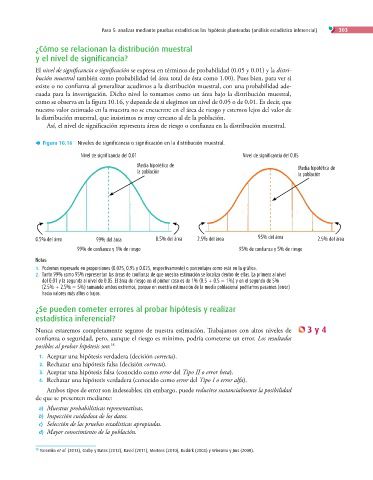
Figura 10.16 Niveles de significancia o significación en la distribución muestral.
Nivel de significancia del 0.01 Nivel de significancia del 0.05
Media hipotética de Media hipotética de
la población
la población
0.5% del área 99% del área 0.5% del área 2.5% del área 95% del área 2.5% del área
99% de confianza y 1% de riesgo 95% de confianza y 5% de riesgo
Notas:
1. Podemos expresarlo en proporciones (0.025, 0.95 y 0.025, respectivamente) o porcentajes como está en la gráfica.
2. Tanto 99% como 95% representan las áreas de confianza de que nuestra estimación se localiza dentro de ellas. La primera al nivel
del 0.01 y la segunda al nivel de 0.05. El área de riesgo en el primer caso es de 1% (0.5 0.5 1%) y en el segundo de 5%
(2.5% 2.5% 5%) sumando ambos extremos, porque en nuestra estimación de la media poblacional podríamos pasarnos (error)
hacia valores más altos o bajos.
¿Se pueden cometer errores al probar hipótesis y realizar
estadística inferencial?
Nunca estaremos completamente seguros de nuestra estimación. Trabajamos con altos niveles de 3 y 4
confianza o seguridad, pero, aunque el riesgo es mínimo, podría cometerse un error. Los resultados
posibles al probar hipótesis son: 18
1. Aceptar una hipótesis verdadera (decisión correcta).
2. Rechazar una hipótesis falsa (decisión correcta).
3. Aceptar una hipótesis falsa (conocido como error del Tipo II o error beta).
4. Rechazar una hipótesis verdadera (conocido como error del Tipo I o error alfa).
Ambos tipos de error son indeseables; sin embargo, puede reducirse sustancialmente la posibilidad
de que se presenten mediante:
a) Muestras probabilísticas representativas.
b) Inspección cuidadosa de los datos.
c) Selección de las pruebas estadísticas apropiadas.
d) Mayor conocimiento de la población.
18 Yaremko et al. (2013), Cozby y Bates (2012), Ravid (2011), Mertens (2010), Buskirk (2008) y Wiersma y Jurs (2008).
www.elosopanda.com | jamespoetrodriguez.com