
Page 339 - METODOLOGIA DE LA INVESTIGACION-Roberto Hernández Sampieri
P. 339
308 Capítulo 10 Análisis de datos cuantitativos
Figura 10.18 (continuación)
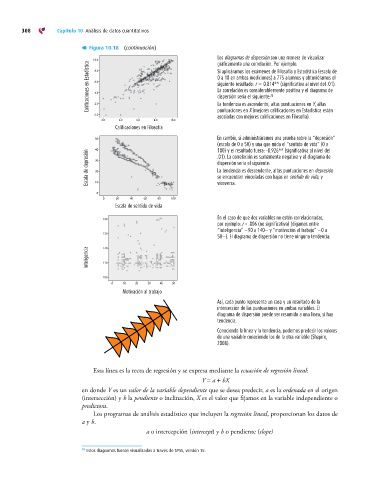
Los diagramas de dispersión son una manera de visualizar
10.0 gráficamente una correlación. Por ejemplo:
Calificaciones en Estadística 6.0 0 a 10 en ambas mediciones) a 775 alumnos y obtuviéramos el
8.0
Si aplicáramos los exámenes de Filosofía y Estadística (escala de
siguiente resultado: r 0.814** (significativa al nivel del .01).
La correlación es considerablemente positiva y el diagrama de
4.0
20
dispersión sería el siguiente:
2.0
puntuaciones en X (mejores calificaciones en Estadística están
0.0 La tendencia es ascendente, altas puntuaciones en Y, altas
asociadas con mejores calificaciones en Filosofía).
2.0 4.0 6.0 8.0 10.0
Calificaciones en Filosofía
50 En cambio, si administráramos una prueba sobre la “depresión”
(escala de 0 a 50) y una que mida el “sentido de vida” (0 a
40 100) y el resultado fuera: –0.926** (significativa al nivel del
Escala de depresión 30 dispersión sería el siguiente:
.01). La correlación es sumamente negativa y el diagrama de
La tendencia es descendente, altas puntuaciones en depresión
20
se encuentran vinculadas con bajas en sentido de vida, y
10
0 viceversa.
0 20 40 60 80 100
Escala de sentido de vida
140 En el caso de que dos variables no estén correlacionadas,
por ejemplo: r = .006 (no significativa) (digamos entre
“inteligencia” —90 a 140— y “motivación al trabajo” —0 a
130
50—). El diagrama de dispersión no tiene ninguna tendencia:
Inteligencia 120
110
100
0 10 20 30 40 50
Motivación al trabajo
Así, cada punto representa un caso y un resultado de la
intersección de las puntuaciones en ambas variables. El
diagrama de dispersión puede ser resumido a una línea, si hay
tendencia.
Conociendo la línea y la tendencia, podemos predecir los valores
de una variable conociendo los de la otra variable (Shapiro,
2008).
Esta línea es la recta de regresión y se expresa mediante la ecuación de regresión lineal:
Y = a + bX
en donde Y es un valor de la variable dependiente que se desea predecir, a es la ordenada en el origen
(intersección) y b la pendiente o inclinación, X es el valor que fijamos en la variable independiente o
predictora.
Los programas de análisis estadístico que incluyen la regresión lineal, proporcionan los datos de
a y b.
a o intercepción (intercept) y b o pendiente (slope)
20 Estos diagramas fueron visualizados a través de SPSS, versión 15.
www.elosopanda.com | jamespoetrodriguez.com